The problem
When a single prompt is not enough and a chatbot is not the shape of the product.
Some products want a single LLM call to do everything. That works for simple Q&A. It collapses the moment the product has structure: distinct user phases, distinct cognitive tasks, distinct quality standards per output type.
This platform produces extended creative output through a sequence of specialised agents. Each agent has a narrow job, a narrow prompt, and a model chosen for that specific job. Onboarding agents elicit user preferences. Classification agents route requests. Generation agents produce content. Memory-management agents compress prior context. Sensitive-content agents enforce policy. Image-generation agents anchor visual identity across long sequences. The architecture is the product.
Why this needed AI at the core
An LLM-shaped product, not a product with LLMs bolted on.
The platform produces output a human writer would take hundreds of hours to produce, calibrated to the individual user. No team of humans could be in the loop. No template engine could produce it. The model is the only thing that makes the product possible at the price the user is willing to pay.
The engineering challenge is everything around the model: orchestration, memory, cost control, quality gates, privacy. Eighty percent of the work is the part that is not the LLM call.
The model is the cheap part. The architecture around it is the expensive part.
Architecture
How it was built.
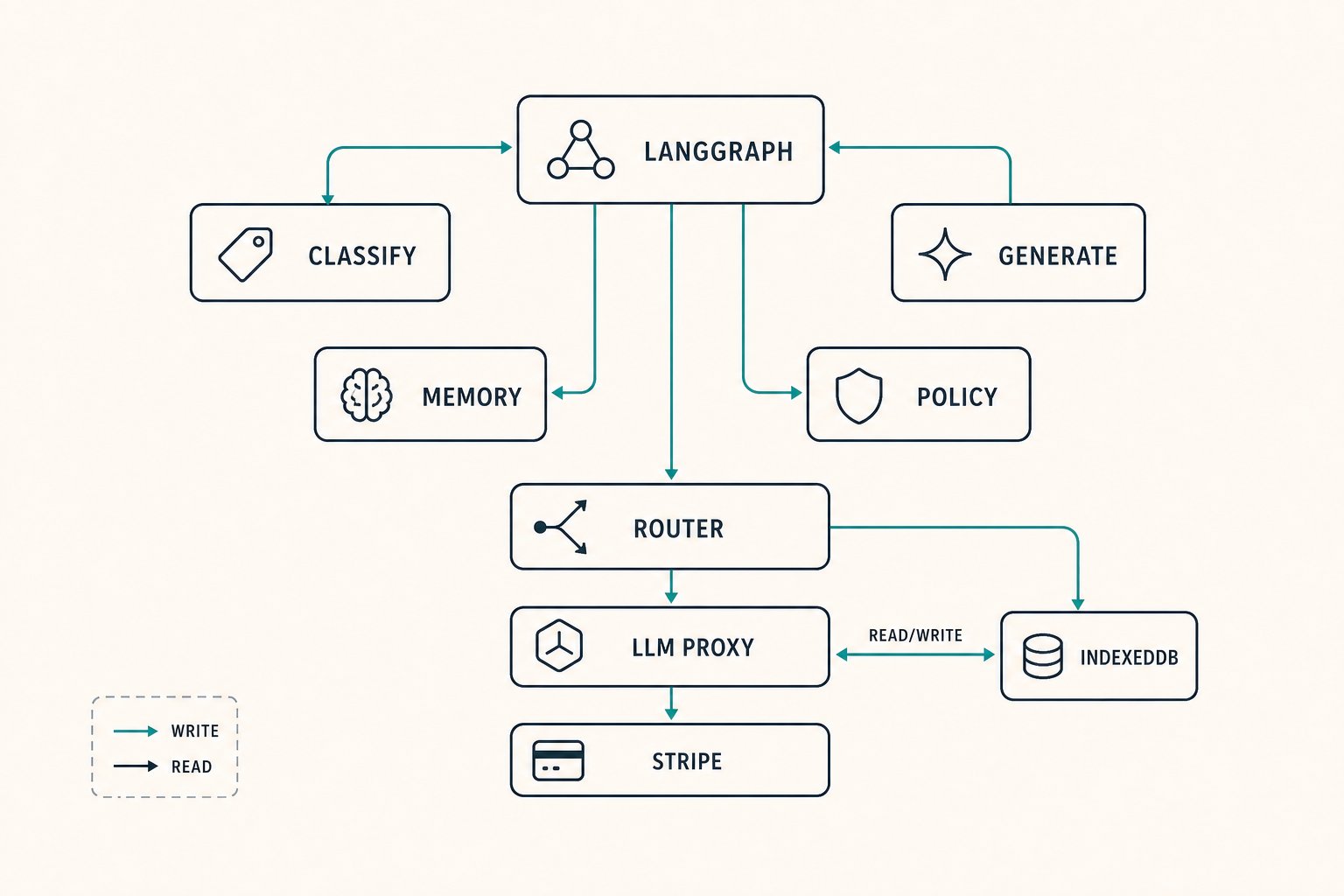
- LangGraph orchestration. The platform is a graph of agent nodes, each with its own prompt and model. Edges are conditional, driven by classifier outputs. State flows through the graph; agents read what they need and write what they produce. The orchestrator is deterministic; the agents are probabilistic. That seam matters.
- 50+ specialised prompts, versioned. Prompts live in source control, indexed by the agent that uses them. Each prompt has a version, a model binding, and a small evaluation set. Changing a prompt without re-running its evaluation set is blocked at the tooling layer.
- Dynamic model routing by task type. Classification routes to a small fast model. Generation routes to a strong model. Memory compression routes to a cheap model. The routing layer is configuration, not code. When a provider releases a better model in a tier, the migration is a config change.
- Metered LLM proxy with cost tracking. Every model call goes through a proxy that tags it with user, agent, prompt version, and cost. Per-user spend rolls up to a Stripe billing layer with hard caps. Operators see, per user, where the cost goes. Cost surprises do not happen.
- Client-side persistence (IndexedDB). The user's full state lives on their device, not on the server. An architectural commitment to privacy. The server holds only what is needed for the current request. This shape is rare in production AI products and was a deliberate inversion of the default.
- Meta-dialogue system. Two distinct conversational registers run side by side: the in-product narration, and a meta layer where the user can query the system itself (why did you do this, what are you remembering, what changes if I change X). Implemented as a parallel agent track on the same state graph.
The hard parts
What broke, and how it got fixed.
Identity persistence across long sessions. A user generates content over many sessions. Image generation has to produce visually consistent characters across hundreds of outputs. The fix is reference-anchored generation: every image-generation call receives a canonical reference image as conditioning, not a description. Identity drift goes from inevitable to negligible.
Memory compression without losing voice. The conversation context grows. At some point it has to be compressed. Naive summarisation loses the user's voice and the prior decisions. The fix is structured compression: separate facts, preferences, and narrative state, summarise each on its own schedule, never collapse them into one paragraph.
Sensitive content with auditable guardrails. The platform handles material that requires policy enforcement. Guardrails are agent-level, with explicit refusal traces logged. Operators can audit refusals and false-positive rates, not just trust a black-box safety filter.
Stripe + LLM cost reconciliation. Real-time LLM spend has to map cleanly to invoiced billing periods. The reconciliation layer treats LLM calls like any other metered resource: cost ledgers, period closes, refund mechanics for failed generations.
Results
What it produced.
The platform is the demonstration that I build AI products, not AI features. The architecture is the answer to a class of brief I see often: we want a real product on top of LLMs, not a chatbot with our logo. The technical patterns here transfer cleanly to enterprise contexts where the same shape applies — domain-specialised agents, cost-controlled orchestration, auditable model behaviour.