The problem
Most companies try the same thing, and hit the same wall.
The pattern repeats. A team connects a chatbot to their internal documents so people can ask questions and get answers back. It demos beautifully. In production, three problems show up. The documents get cut into pieces badly, so answers lose their context. The search pulls passages that sound related but answer the wrong question. And the system cannot explain why it gave the answer it did, so nobody can fix it.
The brief was to build a platform any team could point at their own documents and ship without falling into those traps. Not a one-off. The reusable foundation underneath every future project like it.
Why this needed AI
Document understanding is the part that classical NLP could never do.
Older systems segment documents by structural rules (headers, paragraphs, fixed token counts). The result is brittle and corpus-specific. Procurement contracts, scientific papers, internal wikis, and product specs all have different document grammars, and a one-size chunker fails all of them.
An LLM-driven semantic chunker can read intent. It segments on meaning boundaries, not formatting boundaries. The system uses that capability as the chunking primitive, and pushes a second LLM pass over the resulting catalog for enrichment: title, summary, entity extraction, topic taxonomy, and a synthetic question set used for downstream evaluation.
None of this is bolted-on AI. The LLM sits at the centre of the data model, with deterministic engineering wrapped around it.
Architecture
How it was built.
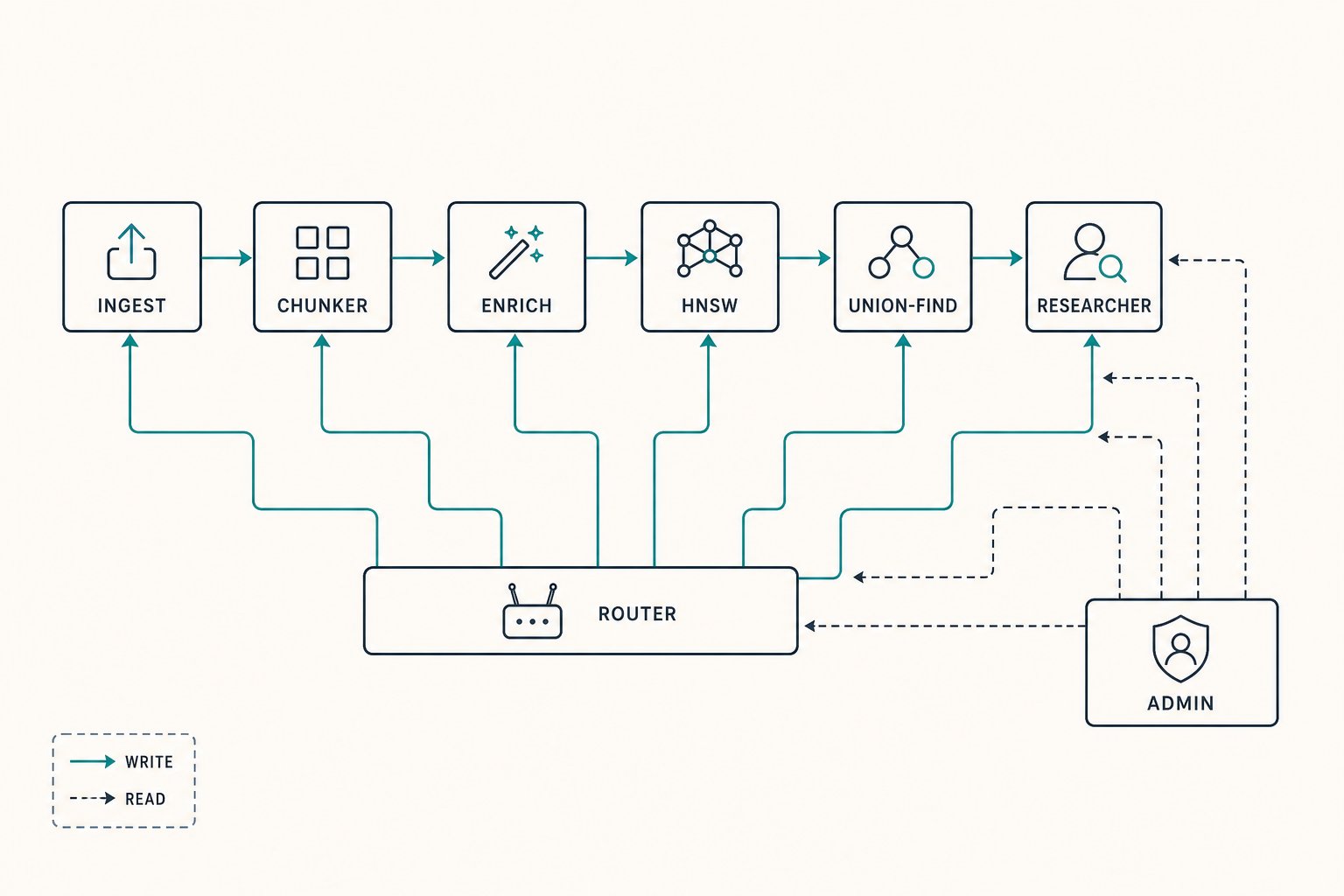
-
Incremental indexing. Google Drive (or any source) is polled by
modifiedTimeplus MD5 hash. The system never reprocesses unchanged documents. Cost of re-ingestion drops with corpus stability. - Semantic sliding-window chunker. An LLM walks the document with a windowed context, emitting chunk boundaries on meaning shifts rather than token counts. Overlaps preserved across boundaries so retrieval never lands mid-thought.
- Two-phase catalog enrichment. Phase one: LLM enrichment per chunk (title, summary, entities, topic, synthetic Q&A). Phase two: HNSW vector index over the enriched space, then a Union-Find pass to decluster — collapsing near-duplicate chunks that the LLM enrichment had over-fragmented. The declustering step alone cut catalog size by ~35% on a typical corpus while improving retrieval precision.
- Agentic researcher loop. Queries are answered by a Grok-class small model running a self-evaluating loop: retrieve, draft, score the draft against the query, retrieve more if confidence is low, iterate. A larger model is only invoked when the small model flags low confidence. Cost-effective by construction.
- Multi-provider LLM routing. Each step of the pipeline (chunking, enrichment, embedding, generation) is routed to the right model independently. Different tasks, different cost-and-latency profiles. Provider migrations are configuration, not code changes.
- SSE-streaming admin panel. Operators see every retrieval, every score, every re-ranking, every model call, in real time. When a query goes wrong, the operator can read the trace and fix the system. This is the part that distinguishes production from demo.
The hard parts
Where this got interesting.
HNSW declustering via Union-Find. An LLM enriching chunks independently will generate semantically near-duplicate summaries for genuinely near-duplicate chunks. A naive vector index leaves you with N copies of the same point. A Union-Find pass over an HNSW proximity graph collapses these into representative classes without losing retrieval recall. Most teams skip this step and pay for it in retrieval quality.
Self-evaluating agentic loops. A small model scoring its own draft is biased toward confidence. The fix: the scoring rubric is anchored against the retrieval evidence, not the draft text. The model can only score high if the evidence supports it. Cheap escape valve to a larger model when scores fall below threshold.
Configurability without complexity. Every knob a configuration file can expose is a knob the operator has to understand. The platform exposes the small set of decisions that matter (chunking strategy, model routing, retrieval depth) and hides the rest behind sensible defaults discovered empirically.
Results
What it produced.
Delivered as a working platform with a streaming admin interface. The configurability is the product. A new domain corpus comes online with a configuration file and a few hours of tuning, not a re-implementation.
This is what I reach for whenever a client comes in with the question, can we make our documents searchable in plain language? The answer is yes. The version that survives real use looks like this, not like something you wire together with ChatGPT in an afternoon.