The problem
Turning a manuscript into a finished video should cost a manuscript, not a film crew.
The unit economics of video content used to be set by the cost of human labour at every stage: an illustrator, a voice actor, a director, an editor, a sound engineer. AI tools have collapsed each of those individually. The hard part is making them work together at length without the seams showing.
This pipeline takes a manuscript of arbitrary length and produces narrated video with visually consistent characters and a single coherent narrator voice. A full-length piece, not a single clip. The brief was end-to-end automation with quality high enough that the output is the product, not a draft.
Why this needed AI everywhere
Every stage is a different model, and the consistency happens between them.
The text-to-shot decomposition is an LLM task. Character description and identity anchoring is a multimodal task. Image generation is a diffusion task. Voice synthesis is a TTS task. Audio-video alignment is a deterministic task on top of all of them.
No single model does this. The engineering is in stitching them together in a way that preserves identity across modalities. A character described in chapter one has to look the same in chapter twelve and sound the same throughout. Drift is the enemy.
Architecture
How it was built.
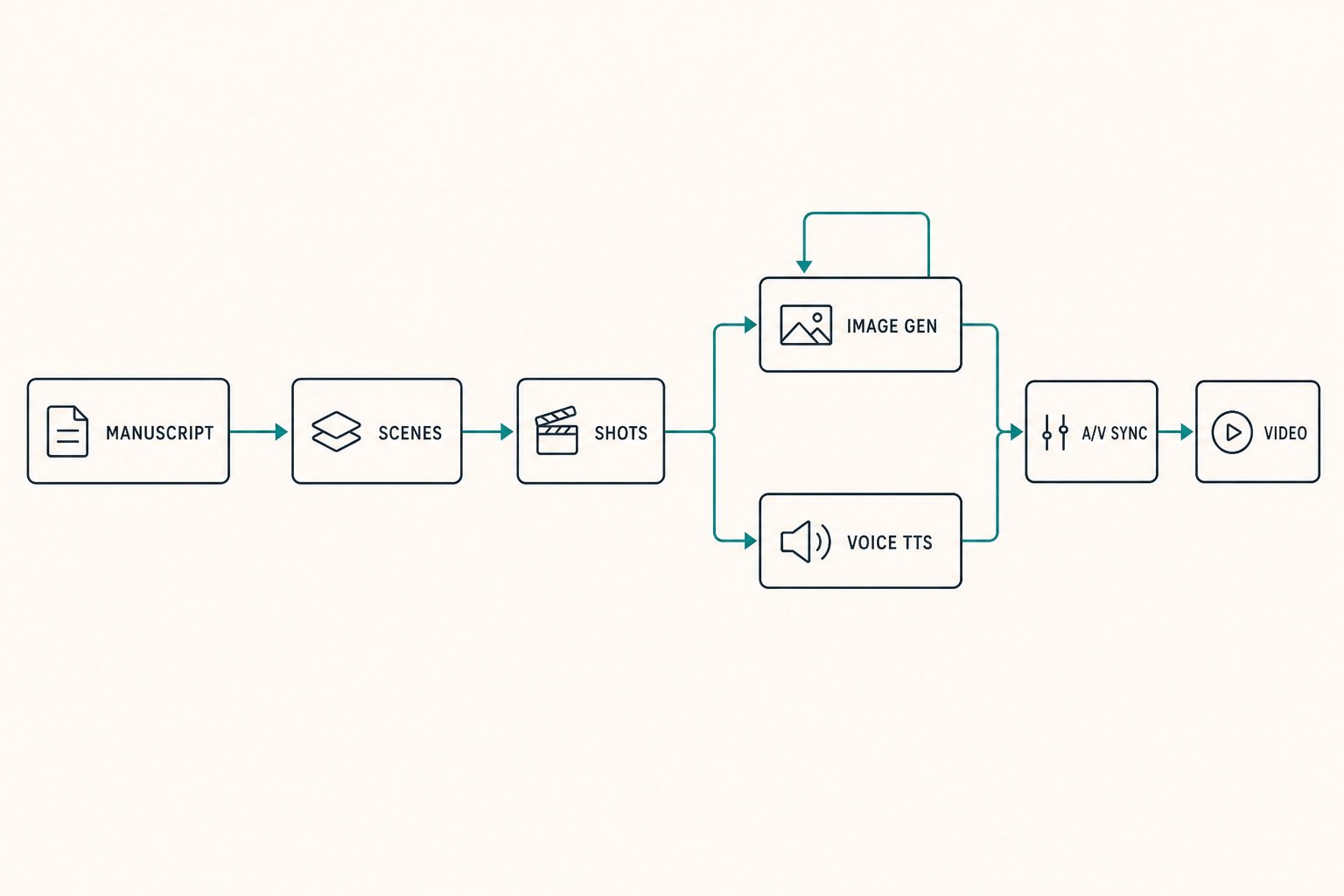
- Scene segmentation. An LLM decomposes the manuscript into scenes, then into shots. Each shot has a setting, a cast list (which characters are present), a narrative function, and a target duration. The decomposition is the spine of the pipeline; every downstream stage references shot IDs.
- Character extraction and identity anchoring. A first pass enumerates every character in the manuscript and writes a canonical visual description. A second pass generates the canonical reference image for each. From that point forward, every image-generation call for a shot receives the character's reference image as conditioning. Identity drift across hundreds of generations falls to near zero.
- Image generation per shot. Each shot prompt is composed from setting plus character references plus narrative beat. Generations are evaluated against the shot's intent by a vision-language model before being accepted. Failed shots are retried with adjusted prompts, not silently shipped.
- Voice synthesis with prosody control. Narration is generated through a TTS provider with a stable voice clone. Prosody markers are inserted by an LLM pre-pass based on narrative beat (calm, tense, climactic). The narrator sounds like one human across hours of audio.
- Audio-video synchronisation. Audio durations come back from TTS; shot durations are stretched or compressed to match using FFmpeg, never the other way around. Audio is sacred; video bends to it. The reverse produces robotic pacing.
- Quality gates at every stage. Each stage emits structured artefacts that the next stage consumes. A failure at any stage halts the run and surfaces the offending artefact for human review. No silent failures, no looks fine automation.
The hard parts
Where the seams threaten to show.
Character drift across diffusion models. A character generated in twenty different shots will tend to drift — different hair, different age, different ethnicity. Reference-anchored conditioning is the only reliable fix. Text prompting alone fails at scale.
Voice consistency under variable text. A TTS voice clone holds well across paragraphs of similar register and breaks at register shifts (dialogue, internal monologue, technical asides). The pipeline tags every passage with register before TTS and switches voice configurations accordingly.
Cost control. A manuscript can produce hundreds of shots, each with an image generation and several minutes of TTS. Naive pipelines burn money. Aggressive caching of accepted artefacts, plus tiered model routing (cheap model for first attempt, frontier model only on retry) keeps unit cost predictable.
Continuity tracking. Time of day, location, what each character is wearing, what props are visible — all of this has to stay consistent across shots that are generated in parallel. A shared continuity state machine threads through every shot prompt.
Results
What it produced.
This is one example of a complex pipeline taken seriously as engineering. The point is not the volume of video it can produce. The point is the pattern. The same architecture transfers to whatever a team has to make at scale: training video, internal communications, product explainers, or a different shape entirely, like turning a stack of documents into something a person can actually watch. The expensive part was always the human labour at every stage. This is what it looks like once that labour is automated without the seams showing.