The problem
A conversational AI that forgets every Monday is not an assistant. It is a stranger you brief again.
Off-the-shelf coding agents and chat assistants reset at the start of every session. Context lives inside one conversation and dies with it. A senior practitioner working across half a dozen ongoing engagements cannot afford that: by Wednesday the agent has forgotten Monday's architectural decision, and Friday's planning conversation has no idea what was built on Thursday.
The brief I gave myself was simple. Build an assistant that remembers, that lets multiple specialised conversations share the same underlying knowledge, that curates its own library in the background without my supervision, and that can be cloned and re-specialised per client without rebuilding the substrate.
Why this needed AI
The reason a database with a chat window does not solve this.
Persistent memory is the easy half. The hard half is curation. A naive append-only log of every conversation drowns the assistant in irrelevance within a week. What is needed is a system that, between conversations, decides what was worth keeping, where it belongs, what it consolidates with, and what should be pruned.
That decision is judgement work. It is the kind of task humans do badly when tired and computers cannot do with rules. An LLM in a background curation role, given the right prompts and the right view of what changed, does it well enough to run unsupervised. The whole framework is built around that bet, and after a year of daily use the bet has held.
Persistence is plumbing. The interesting part is what runs in the background while the user is asleep.
Architecture
How it is built.
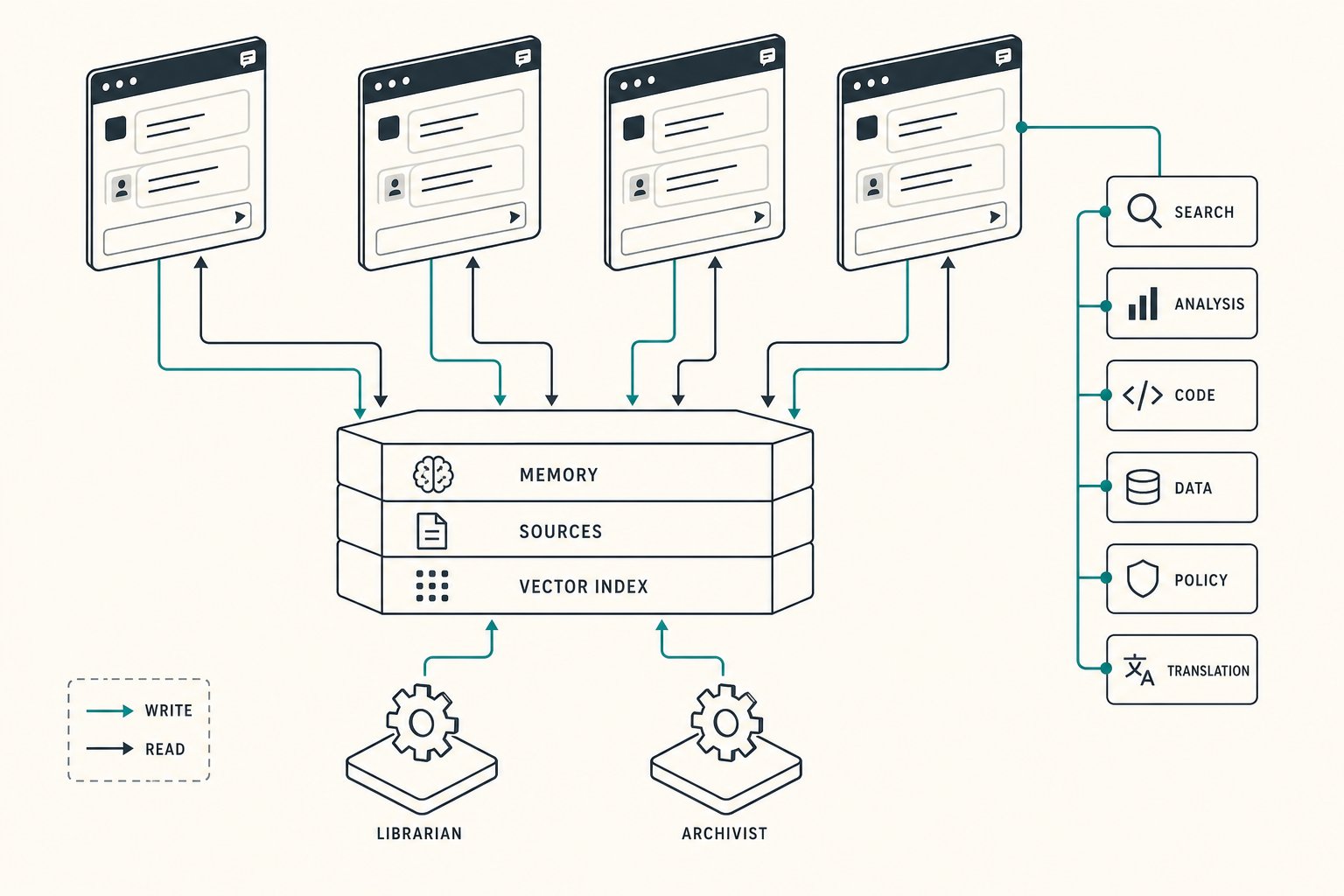
Six layers, each doing one thing.
-
Multi-conversation surface. Several parallel conversations can run against the same assistant — one for engineering work, one for business strategy, one for a specific client engagement — each with its own scope, all sharing the underlying memory. A
consciousness.mdfile gives every conversation cross-awareness of what the others have been doing without bleeding their state. -
Shared memory plus source canon. Two distinct stores.
memory/holds curated notes the assistant writes and rewrites: identity, learnings, decisions, project state.sources/holds canonical archived material — PDFs, research, reference documents the user keeps and the assistant cites but never edits. Both are indexed into separate vector spaces and searched together. - Researcher hook on every turn. Before the assistant sees a user message, an LLM-driven researcher analyses what knowledge the turn will need and runs multi-axis semantic search across memory and sources. The result is injected directly into the assistant's context as memory excerpts, with a stated reason for each piece. No second tool call required.
- Background curation agents. After every turn a librarian (Haiku) reads the exchange and files what is worth remembering — updating notes, consolidating scattered entries, pruning stale content. Every ten turns an archivist sweeps the wider library for duplicates and decay. Both run unsupervised and the user never sees them work.
- Skills and workers. Specialist modes can be loaded into the conversation — a code auditor, a researcher, a humanizer, an image-generation specialist — each with its own prompt, tools, and discipline. Workers spawn sub-conversations in parallel or in the background, so heavy delegated work runs without blocking the main thread.
-
Per-client specialisation. The whole substrate is a template. A single
new.shcommand scaffolds a fresh assistant with its own identity, its own memory folders, its own domain skills. The shared infrastructure syncs from a central template on every start, so improvements to the framework propagate to every client instance without manual upgrades.
The hard parts
What made this engineering, not prompting.
Context drift across long conversations. A turn-30 assistant sees turn-5 as a heavily compacted summary, and cannot feel the loss. The fix is a per-conversation workspace file that is re-injected verbatim every turn — load-bearing decisions live there, not in the conversational stream, so they survive every compaction.
The curation feedback loop. A librarian that files too aggressively pollutes memory with noise; one that files too conservatively forgets what mattered. Tuning that prompt, and giving the librarian its own working notes that the user can edit to course-correct, took longer than the rest of the system combined.
Worker lifecycle as a real abstraction. Workers are not function calls. They run in the background, persist after completion, and can be re-engaged with follow-up questions that preserve their context. Getting the employment-and-activity state model right — when a worker is done, when it is dismissed, when it is waiting on its principal — was the difference between "useful parallelism" and "orphaned processes everywhere."
Two indexes, one search. Curated memory and source canon need different write policies (memory mutates, sources are read-only) but a single search surface. Splitting them into two vector spaces with a unified query path, and surfacing source provenance differently from memory provenance in the UI, was a small architectural decision that pays back every day.
Results
What it produced.
Anvil is the assistant I work with every day, and the substrate underneath every other engagement I run. It is also the architecture I propose when a client wants an internal assistant of their own: not a chat window on top of their data, but a real working partner with persistent memory, background curation, and specialised modes for the work that actually fills their week.
The Executive Network Intelligence build for the Group CFO is the first scheduled migration onto this substrate. Once it lands there, the executive will be able to chat with her own network directly — the data, the scoring, the outreach state, all reachable through a conversational surface that remembers what she said about a contact six months ago.